📑TL; DR: MAG-Edit is the first method specifically designed to address localized image editing in complex scenarios without training.
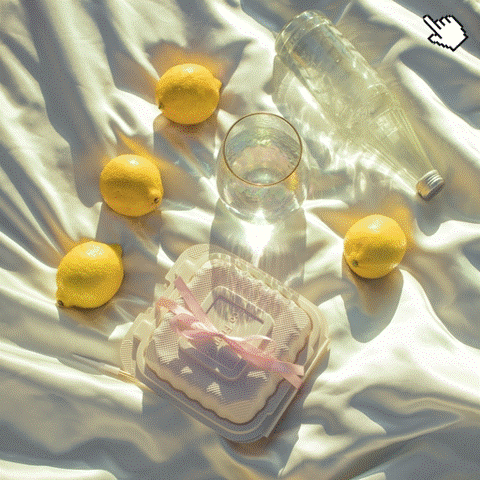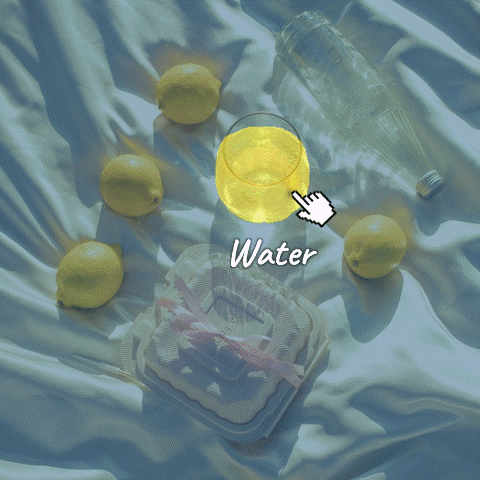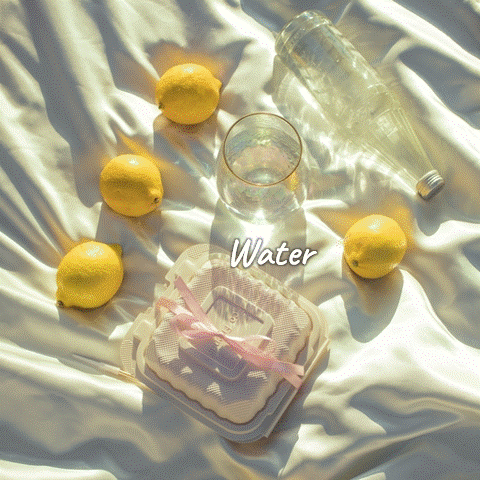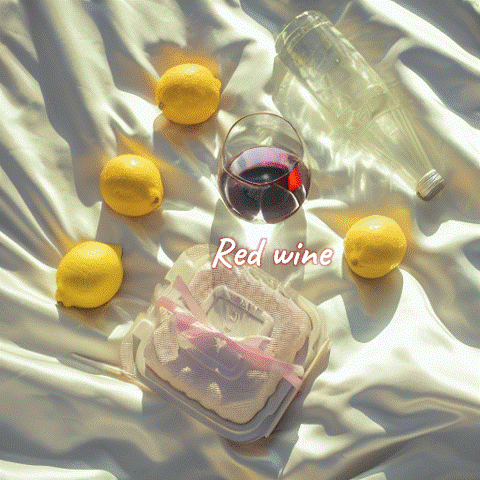
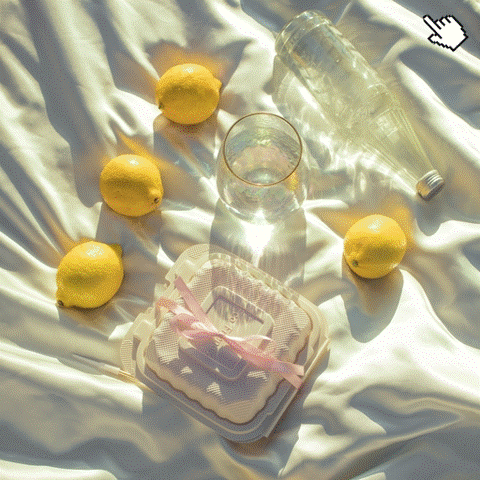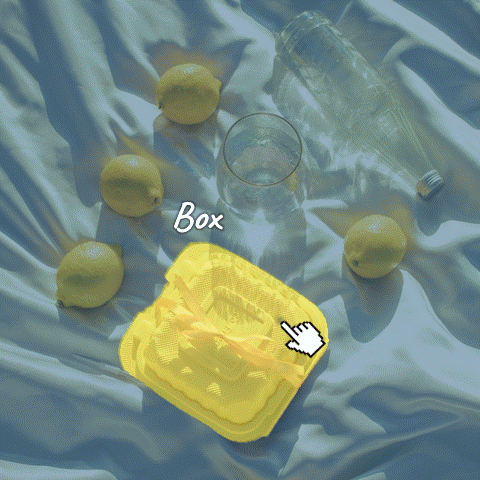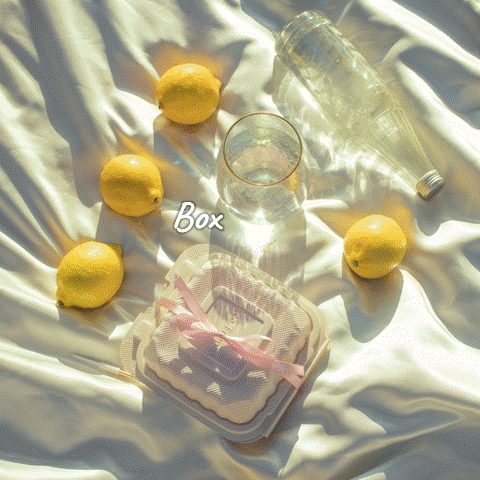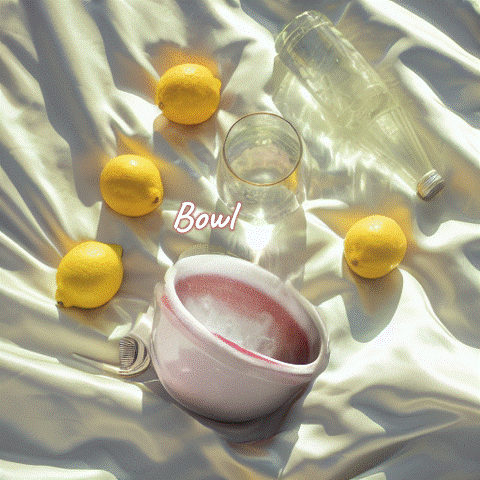
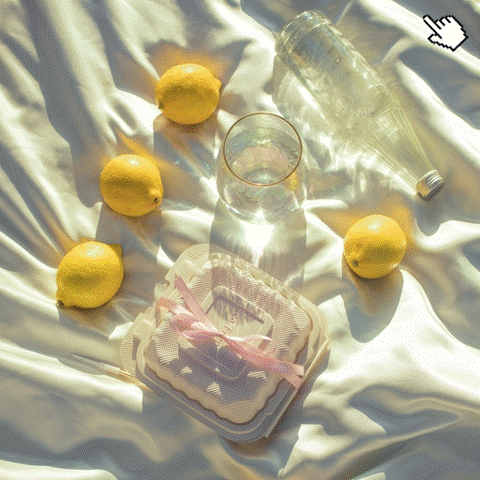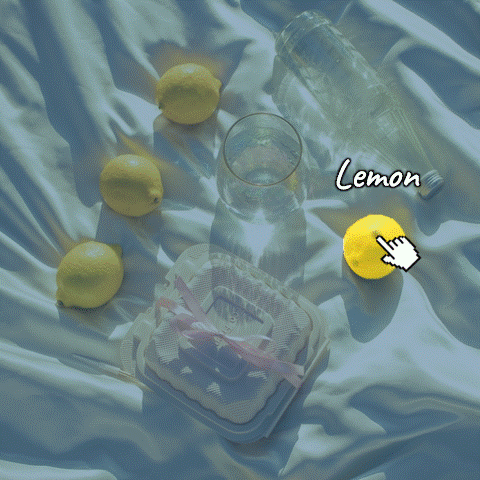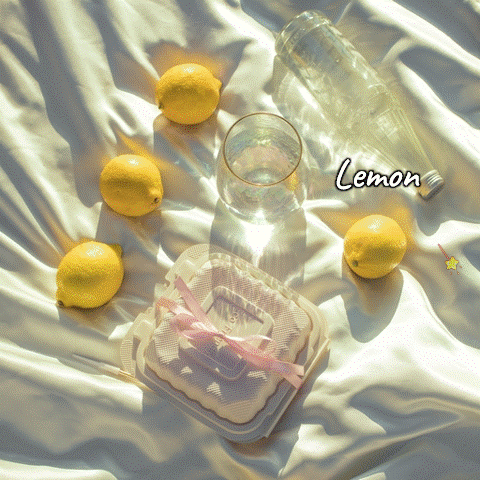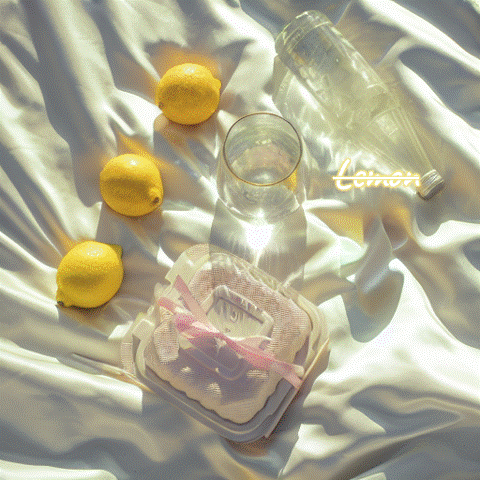
Source Image

Editing Result

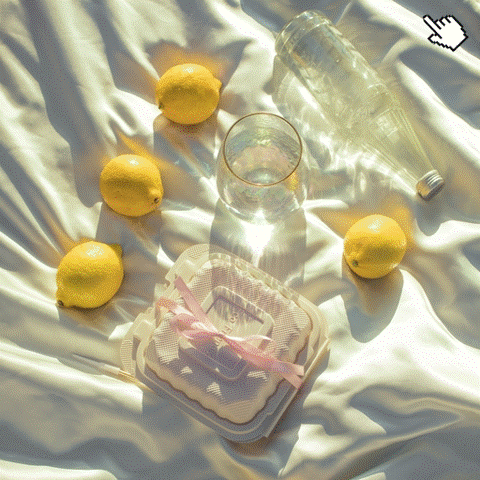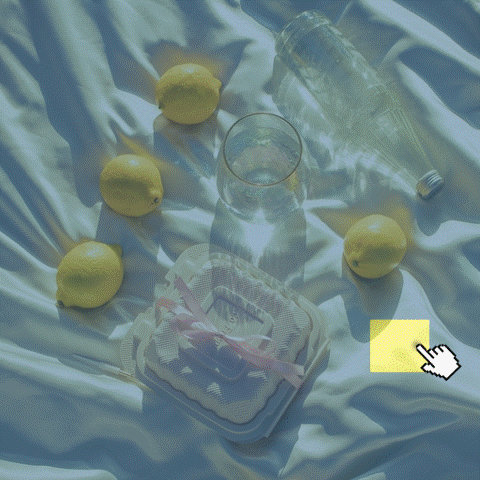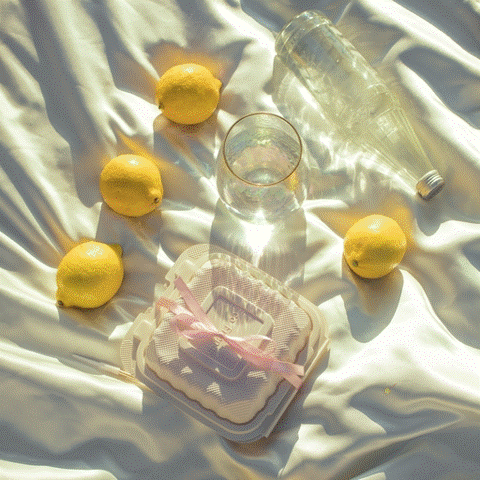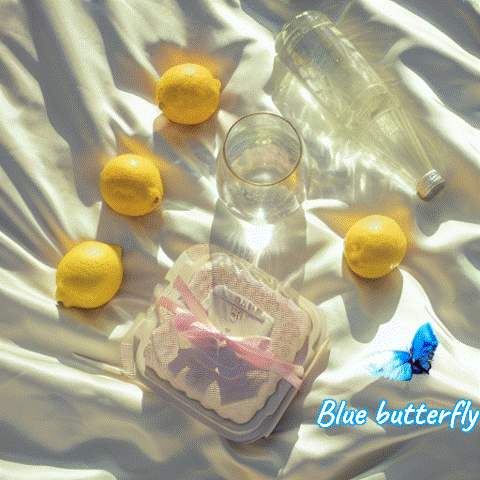
Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result
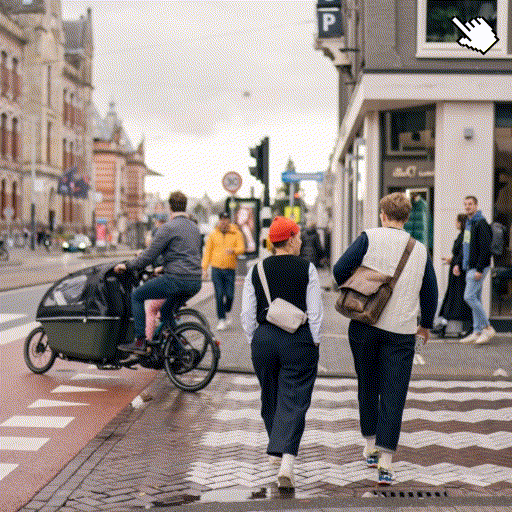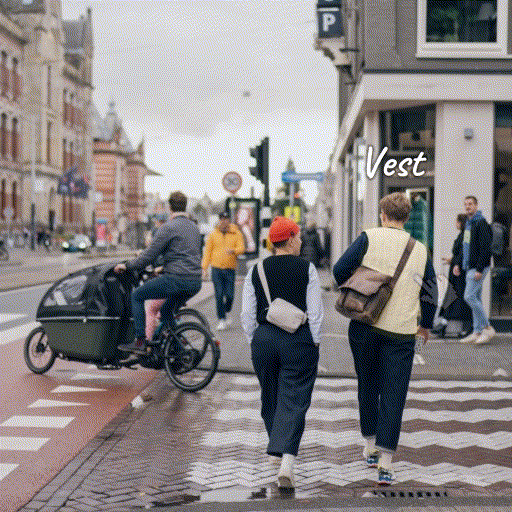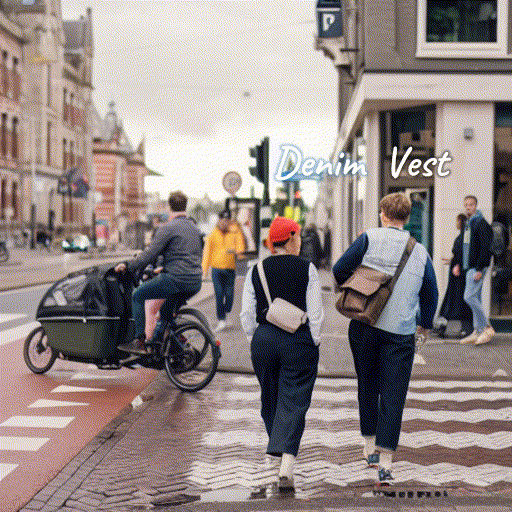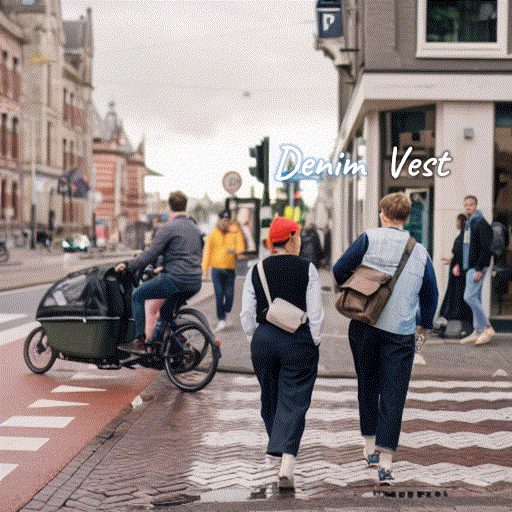
Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Source Image

Editing Result

Recent diffusion-based image editing approaches have exhibited impressive editing capabilities in images with simple compositions. However, localized editing in complex scenarios has not been well-studied in the literature, despite its growing real-world demands. Existing mask-based inpainting methods fall short of retaining the underlying structure within the edit region. Meanwhile, mask-free attention-based methods often exhibit editing leakage and misalignment in more complex compositions. In this work, we develop MAG-Edit, a training-free, inference-stage optimization method, which enables localized image editing in complex scenarios. In particular, MAG-Edit optimizes the noise latent feature in diffusion models by maximizing two mask-based cross-attention constraints of the edit token, which in turn gradually enhances the local alignment with the desired prompt. Extensive quantitative and qualitative experiments demonstrate the effectiveness of our method in achieving both text alignment and structure preservation for localized editing within complex scenarios.
The trade-off between fidelity and editability in localized image editing within complex scenarios presents significant challenges.

Given that cross-attention (CA) maps in pre-trained T2I diffusion models effectively capture the correlation between input features and text embeddings,our key insight is that adjusting the noise latent feature to attain higher CA values significantly enhances its alignment with the corresponding text prompt. As a result, we propose locally optimizing the noise latent feature during the inference stage by maximizing two distinct mask-based CA constraints tailored for the target editing prompt. The constraints aims to maximize two aspects of ratios:
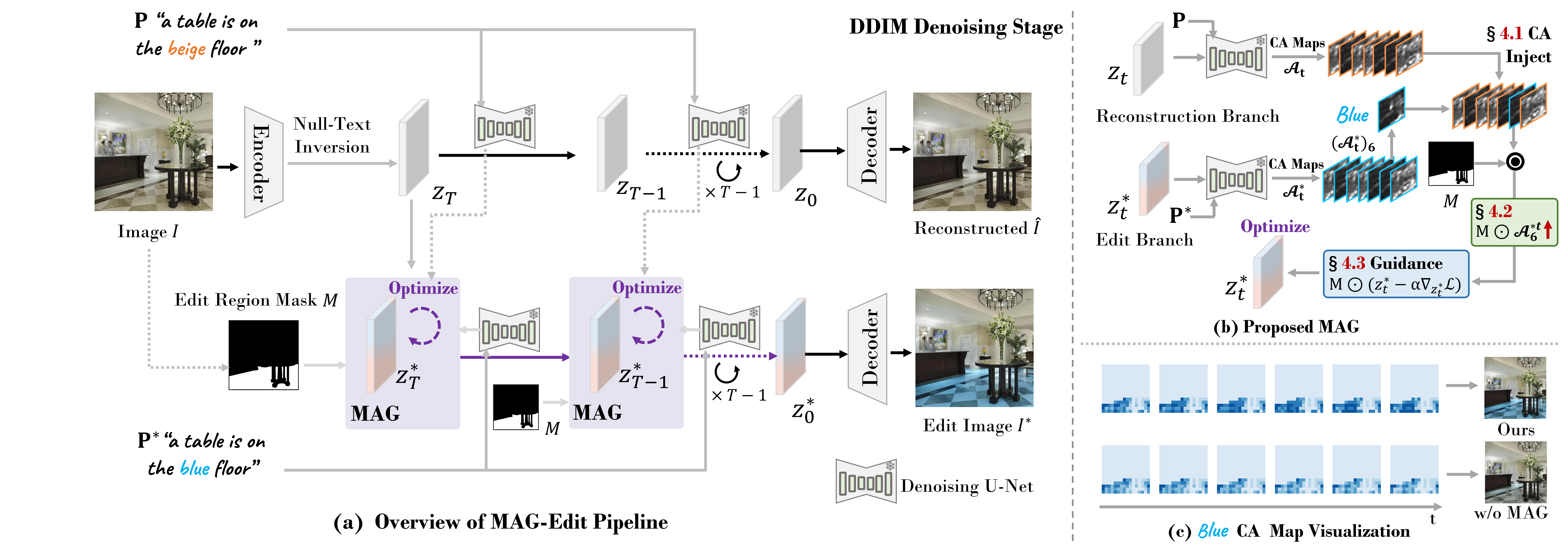
High-level overview of the proposed MAG-Edit framework.

















@article{mao2023magedit,
title={MAG-Edit: Localized Image Editing in Complex Scenarios via $\underline{M}$ask-Based $\underline{A}$ttention-Adjusted $\underline{G}$uidance},
author={Qi Mao and Lan Chen and Yuchao Gu and Zhen Fang and Mike Zheng Shou},
year={2023},
journal={arXiv preprint arXiv:2312.11396},
}[1] Omri Avrahami, Dani Lischinski, and Ohad Fried. Blended diffusion for text-driven editing of natural images. In CVPR, pages 18208–18218, 2022.
[2] Guillaume Couairon, Jakob Verbeek, Holger Schwenk, and Matthieu Cord. Diffedit: Diffusion-based semantic image editing with mask guidance. In ICLR, pages 1–22, 2023.
[3] Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. In ICLR, pages 1–36, 2023.
[4] Narek Tumanyan, Michal Geyer, Shai Bagon, and Tali Dekel. Plug-and-play diffusion features for text-driven image-to-image translation. In CVPR, pages 1921–1930, 2023.
[5] Qian Wang, Biao Zhang, Michael Birsak, and Peter Wonka. Instructedit: Improving automatic masks for diffusion- based image editing with user instructions. arXiv preprint arXiv:2305.18047, 2023.
[6] Kai Zhang, Lingbo Mo, Wenhu Chen, Huan Sun, and Yu Su. Magicbrush: A manually annotated dataset for instruction- guided image editing. In NeurIPS, 2023.
[7] Zhixing Zhang, Ligong Han, Arnab Ghosh, Dimitris N Metaxas, and Jian Ren. Sine: Single image editing with text-to-image diffusion models. In CVPR, pages 6027–6037, 2023.
[8]Senmao Li, Joost van de Weijer, Taihang Hu, Fahad Shahbaz Khan, Qibin Hou, Yaxing Wang, and Jian Yang. Stylediffusion: Prompt-embedding inversion for text-based editing. arXiv preprint arXiv:2303.15649, 2023.
[9]Ligong Han, Song Wen, Qi Chen, Zhixing Zhang, Kunpeng Song, Mengwei Ren, Ruijiang Gao, Yuxiao Chen, Di Liu, Qilong Zhangli, et al. Improving negative-prompt inversion via proximal guidance. arXiv preprint arXiv:2306.05414, 2023.
[10]Xuan Ju, Ailing Zeng, Yuxuan Bian, Shaoteng Liu, and Qiang Xu. Direct inversion: Boosting diffusion-based editing with 3 lines of code. arXiv preprint arXiv:2310.01506, 2023.
 MAG-Edit: Localized Image Editing in Complex Scenarios via
MAG-Edit: Localized Image Editing in Complex Scenarios via 





































































